I feel like everyone knows this warm feeling, when after days and days of doing something in a painfully counter-intuitive way, you finally just get how to do it better. To me, it happens way too often, especially when navigating through the software development world – either by learning about a new, shiny library or after reading through some brilliant article. And each time I just can’t shake off this feeling, that everything I created before was just a big waste of space.
Well, I must admit these were exactly my thoughts, when the concept of server state management libraries finally reached my ears – what a breakthrough it was! Never again did I have to laboriously implement my own cache and deduplication mechanisms, never again did I need to manually set error and loading flags. Big chunks of components responsible for all that, reaching 50 lines at times, now were mere hook calls. Furthermore, not only did I improve my code readability and extensibility this way, but also made my application faster, which I’ll try to show you through our client’s app case study.
TL;DR
Executing your API calls with a server state management library, like SWR or React Query, can significantly simplify your frontend app architecture, while also bringing some performance boosting features to the table. Cache implementation, using React Query, proved to be very performant and helped make our client’s product much better. In the case of new projects, it’s worth considering utilizing such a library from the very beginning, because with a small amount of work you can avoid a lot of server state problems later.
Pulling the data through spaghetti
Tale as old as time: a new, exciting project is starting, client provides a few requirements, we expect a few modules but nothing big or scary. We want to produce a walking skeleton as fast as we can, so we don’t care too much about handling our frontend API calls. We need them here, we need them there, so without thinking we just shoot for the data from any place in the code. Assuming we keep all the direct call methods in one shared interface, the resulting architecture would look somewhat like this:
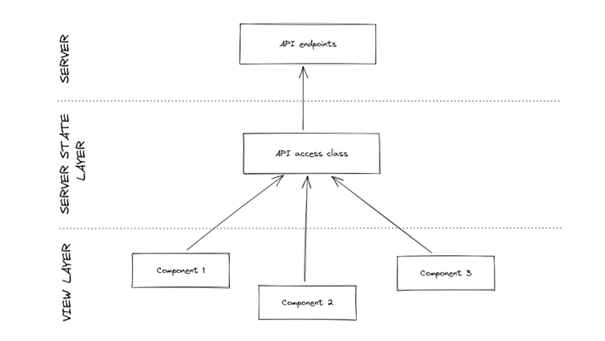
Pretty straightforward, right? Each component deals with the resulting data on its own, saving its state, and everything just sort of works. But then, the multiple models used for the same entity start to look different, one of the components needs to show a loader, and the client requested a browser cache implementation. Each of these requirements are fully expected and understandable, so developers jump straight into action.
Sadly, without a clear idea on how to implement a server state layer, ways of fetching the server data start to multiply. Cache must store sever data, but at the same time it has to be generic enough to hold a multitude of entities, which places it in this weird limbo between view and server state layers. Somewhere else, someone was clever enough to wrap API calls with custom hooks, despite other parts of the system already directly using the API access interface. Additionally, we have to write some mappings from entity to view model, which usually ends up directly in the component code. All that causes our straightforward architecture to morph into a tangled mess, while components start to accommodate way too much code, which would make Uncle Bob really unhappy:
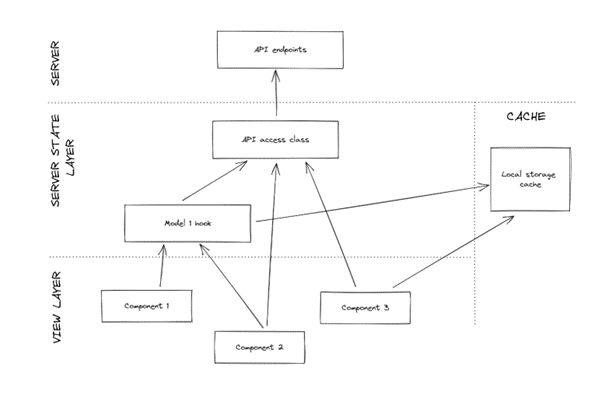
Not so clear anymore, huh? As expected, developers also start to get increasingly frustrated, because at this point, there are at least three different ways to fetch the same data, making our backend-centered colleagues really anxious about doing anything in the frontend project at all - it’s hard to blame them, really! Sharing the same data in multiple places in the system started to be a big problem, because we had to fetch it separately, while making sure it always stays fresh. I mean, we have to have up-to-date data everywhere, right?
The description above more or less paints the picture of the state of one of our client’s projects just as I was joining it. And when suddenly we realised there’s something wrong somewhere in the three hundred lines of local storage-based cache implementation code, and I was the one tasked with fixing it, it almost made me cry - and these were not the tears of joy mind you! That’s when we decided it’s time to untangle this slowly tightening knot.
Cutting through the knots with React Query
The most burning issue was replacing the custom cache implementation with a library – more experienced coworkers suggested SWR or React Query, and we went for the latter, because it was more configurable, offered highly optimized cache and generally was better suited to our needs, while also utilizing stale-while-revalidate data strategy (more on that here). The project already employed that strategy, but it was scattered across various components and hooks, so any library that had it built-in was another way for us to reduce the codebase.
So, with React Query under our metaphorical belt, we jumped into action. API access class was left untouched, because from the very beginning it was the only place that had direct access to API endpoints, and it seems to me like a good choice. However, only the designated data access hooks were allowed to make use of this class. Each of these new hooks utilized the query and mutation-based hooks provided by React Query and dealt with mapping (finally all in one place), and provided ready to be used, view formatted data. Furthermore, it also returned loading state (making loader or shimmer implementation so easy), as well as a cache invalidation method.
Thus, we have a bunch of data access hooks considered as the only source of truth for the frontend app, that is fetched only once, but also automatically refreshes all the places that use it. And suddenly, just like that, in order to use server state in a component we had to call one hook – no more storing data and loading state directly into components!
What was the biggest benefit though, is that the main task – fixing the cache – resolved itself the moment we started to utilize those hooks everywhere in the application. We were delighted to remove all the custom implementation and replace it with the built-in one provided by React Query, while significantly improving overall app performance thanks to decreasing the backend request count. After these changes were made, this was roughly the resulting architecture:
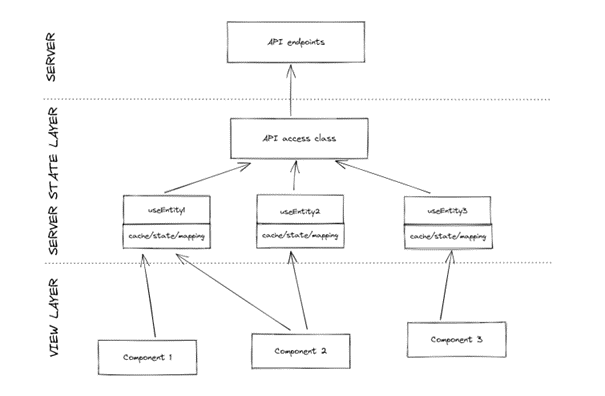
You can clearly see that this very simplified diagram looks somewhat like the one we opened this blog post with. I believe this to be a great sign. We are going back to the initial, simple idea, while retaining all the functionality introduced in the meantime. Now calls to the server state layer are only made through our custom hooks, so the responsibility for dealing with data lies solely with them, separating the server state logic from components rendering the views.
Is this really necessary?
Bearing in mind that incorporating server state management library is additional work, you might’ve thought to yourself “Is this really necessary? In my app, I call only three endpoints, I don’t do any mapping and my app is lightning fast anyway!”. And well, you’re right! However, when making that final decision, please also remember that the example presented above started from the exact same place – I’d even say it’s every project’s starting place!
The thing is, however, that your endpoints, requests and data size will multiply along with client’s expectations and requirements. Why shouldn’t you try and offer the best performance from the very beginning, instead of worrying about it once it starts to be a problem? I truly believe that this approach is worth it, and when you get used to it, dear reader, you’ll find it hard to go back to your previous ways – at least I don’t intend to go back.
Wait, where’s code?!
I tried to make this blog post as simple as possible, without delving too deep into implementation details. However, I want to share our implementation of local storage-based persistence using React Query, and I promise, this one will be way juicier. Please stay tuned for it!